Кроме иерархических методов классификации существует группа итеративных методов кластерного анализа. Сущность их заключается в том, что процесс классификации начинается с задания некоторых начальных условий (количество образуемых кластеров, порог завершения процесса классификации и т. д.). Как и в иерархическом кластерном анализе, в итеративных методах существует проблема определения числа кластеров. В общем случае их число может быть неизвестно. Не все итеративные методы требуют первоначального задания числа кластеров, но позволяют используя несколько алгоритмов, меняя либо число образуемых кластеров, либо установленный порог близости для объединения объектов в кластеры добиваться наилучшего разбиения по задаваемому критерию качества.
К группе итеративных методов принадлежит метод k-средних. Суть метода в следующем.
Пусть имеется n наблюдений, каждое из которых характеризуется p признаками X1, X2,..., Xp. Эти наблюдения необходимо разбить на k кластеров. Сначала из n точек исследуемой совокупности отбираются случайным образом или задаются исследователем исходя из каких-либо априорных соображений k точек (объектов). Эти точки принимаются за эталоны. Каждому эталону присваивается порядковый номер, который одновременно является и номером кластера. На первом шаге из оставшихся (n - k) объектов извлекается точка Xi с координатами (xi1, xi2, ..., xip) и проверяется, к какому из эталонов она находится ближе всего (используется одна из метрик). Эталон заменяется новым, пересчитанным с учетом присоединенной точки, и вес его (количество объектов, входящих в данный кластер) увеличивается на единицу. Если встречаются два или более минимальных расстояния, то i-тый объект присоединяют к центру с наименьшим порядковым номером. На следующем шаге выбирается точка Xi+1 и для нее повторяются все процедуры. Таким образом, через (n - k) шагов все объекты окажутся отнесенными к одному из k кластеров, но на этом процесс разбиения не заканчивается. Что бы добиться устойчивости разбиения по тому же правилу, все объекты X1, X2, ..., Xn опять присоединяются к полученным кластерам, при этом веса продолжают накапливаться. Новое разбиение сравнивается с предыдущим. Если они совпадают, то работа алгоритма завершается. В противном случае цикл повторяется. Окончательное разбиение имеет центры тяжести, которые не совпадают с эталонами, их можно обозначать С1, C2, ..., Ck. При этом каждая точка Xi (i = 1,2, ..., n) будет относиться к такому кластеру l, для которого
ρ(xj,cl) = min ρ(xj,Cj)
Существуют две модификации метода k - средних. Первая предполагает пересчет центра тяжести кластера после каждого изменения его состава, вторая - лишь после того, как будет завершен просмотр всех данных.
Рассмотрим пример. Сельскохозяйственные предприятия (15 предприятий) сравниваются по двум показателям: растениеводству и животноводству. Значения показателей представлены в таблице.
| Растениеводство | Животноводство |
| 2,3 | 0,35 |
| 1,51 | 0,51 |
| 1,17 | 0,29 |
| 1,67 | 0,29 |
| 2,91 | 0,3 |
| 2,45 | 0,38 |
| 1,42 | 0,49 |
| 1,22 | 0,31 |
| 1,85 | 0,29 |
| 2,7 | 0,45 |
| 2,35 | 0,5 |
| 1,6 | 0,45 |
| 1,27 | 0,25 |
| 1,67 | 0,32 |
| 2,73 | 0,34 |
Проведем кластеризацию предприятий используя метод k-средних используя в качестве метрики квадрат евклидова расстояния. Зададим количество кластеров равное трем. Результат кластеризации средствами "Statgraphics" представлен графиком.
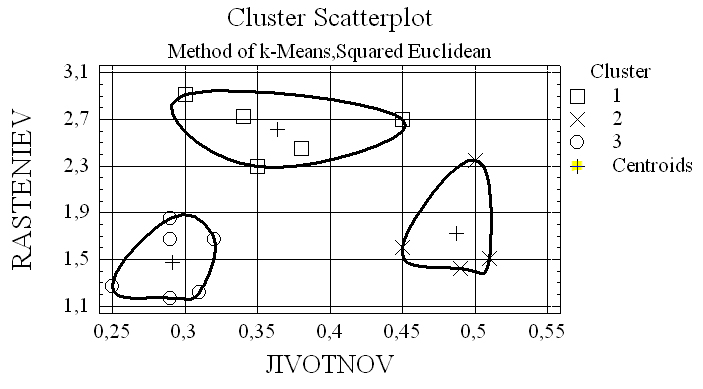
Необходимо еще раз напомнить об обязательной нормализации исходных данных. Ниже приведен график кластеризации методом k-средних без нормализации исходных данных.
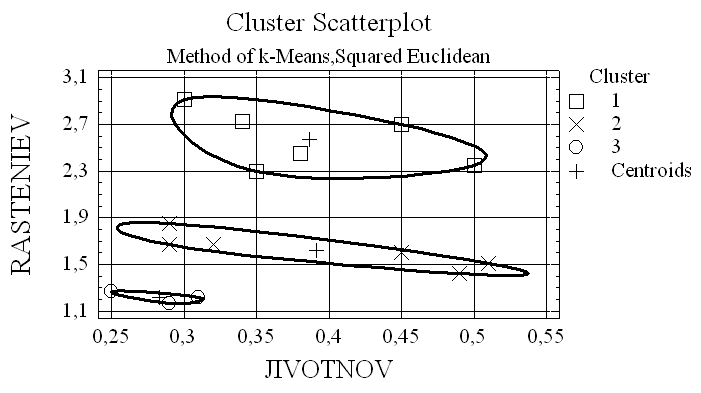
Обратите внимание - размер и состав кластеров в этом случае резко отличается от результата правильной кластеризации.
Вычислительные процедуры большинства итеративных методов классификации сводятся к выполнению следующих действий:
-
Выбор числа кластеров, на которые должна быть разбита совокупность, задание первоначального разбиения объектов и определение центров тяжести кластеров.
-
В соответствии с выбранными мерами близости определение нового состава каждого кластера.
-
После полного просмотра всех объектов и распределения их по кластерам осуществляется пересчет центров тяжести кластеров.
Шаги 2 и 3 повторяются до тех пор, пока следующая итерация не даст такой же состав кластеров, что и предыдущая.
Одним из итеративных методов классификации, не требующих задания числа кластеров, является метод поиска сгущений. Метод требует вычисления матрицы расстояний, затем выбирается объект, который является первоначальным центром первого кластера. Выбор такого объекта может быть произвольным, а может основываться на предварительном анализе точек и их окрестностей.
Выбранная точка принимается за центр гиперсферы заданного радиуса R. Определяется совокупность точек, попавших внутрь этой сферы, и для них вычисляются координаты центра (вектор средних значений признаков). Далее рассматривается гиперсфера такого же радиуса, но с новым центром, и для совокупности попавших в нее точек опять рассчитывается вектор средних значений, который принимается за новый центр сферы и так далее. Когда очередной пересчет координат центра сферы приводит к такому же результату, как на предыдущем шаге, перемещение сферы прекращается, а точки, попавшие в нее, образуют кластер и из дальнейшего процесса кластеризации исключаются. Для всех оставшихся точек процедуры повторяются.