Дискриминантный анализ, как раздел многомерного статистического анализа, включает в себя статистические методы классификации многомерных наблюдений в ситуации, когда исследователь обладает так называемыми обучающими выборками ("классификация с учителем"). Например, для оценки финансового состояния своих клиентов при выдаче им кредита банк классифицирует их по надежности на несколько категорий по ряду признаков. В случае, когда следует отнести клиента к той или иной категории используют процедуры дискриминантного анализа. Очень удобно использовать дискриминантный анализ при обработке результатов тестирования. Так при выборе кандидатов на определенную должность можно всех опрошенных претендентов разделить на две группы - удовлетворяющих и неудовлетворяющих предъявляемым требованиям.
Все процедуры дискриминантного анализа можно разбить на две группы и рассматривать их как совершенно самостоятельные методы. Первая группа процедур позволяет интерпретировать различия между существующими классами, вторая - производить классификацию новых объектов в тех случаях, когда неизвестно заранее, к какому из существующих классов они принадлежат.
Пусть имеется множество единиц наблюдения - генеральная совокупность. Каждая единица наблюдения характеризуется несколькими признаками: xij - значение j-й переменной i-го объекта (i=1,..., n; j=1,..., p). Предположим, что все множество объектов разбито на несколько подмножеств (два и более). Из каждого подмножества взята выборка объемом nk, где k - номер подмножества (класса), k = 1,..., q.
Признаки, которые используются для того, чтобы отличать один класс (подмножество) от другого, называются дискриминантными переменными. Число объектов наблюдения должно превышать число дискриминантных переменных: p<n. Дискриминантные переменные должны быть линейно независимыми. Основной предпосылкой дискриминантного анализа является нормальность закона распределения многомерной величины. Это означает, что каждая из дискриминантных переменных внутри каждого из рассматриваемых классов должна быть подчинена нормальному закону распределения.
Основная идея дискриминантного анализа заключается в том, чтобы определить, отличаются ли совокупности по среднему какой-либо переменной (или линейной комбинации переменных), и затем использовать эту переменную, чтобы предсказать для новых членов их принадлежность к той или иной группе. Канонической дискриминантной функцией называется линейная функция:
dkm = β0 + β1*x1km + ... + βp*xpkm ,
где:
dkm - значение канонической дискриминантной функции для m-го объекта в группе k (m = 1, ..., n, k = 1, ..., g);
xpkm - значение дискриминантной переменной Xi для m-го объекта в группе k;
β0, ..., βp - коэффициенты дискриминантной функции.
С геометрической точки зрения дискриминантные функции определяют гиперповерхности в p-мерном пространстве. В частном случае при p=2 она является прямой, а при p=3 — плоскостью.
Коэффициенты βi первой канонической дискриминантной функции выбираются таким образом, чтобы центроиды (средние значения) различных групп как можно больше отличались друг от друга. Коэффициенты второй группы выбираются также, но при этом налагается дополнительное условие, чтобы значения второй функции были некоррелированы со значениями первой. Аналогично определяются и другие функции. Отсюда следует, что любая каноническая дискриминантная функция d имеет нулевую внутригрупповую корреляцию с d1, d2, ..., dg-1. Если число групп равно g, то число канонических дискриминантных функций будет на единицу меньше числа групп. Однако по многим причинам практического характера полезно иметь одну, две или же три дискриминантных функций. Тогда графическое изображениее объектов будет представлено в одно–, двух– и трехмерных пространствах. Такое представление особенно полезно в случае, когда число дискриминантных переменных p велико по сравнению с числом групп g.
Рассмотрим простой пример. Пусть имеются следующие наблюдения:
| x1 | x2 |
| 1 | 2 |
| 2 | 6 |
| 3 | 1 |
| 4 | 3 |
| 5 | 5 |
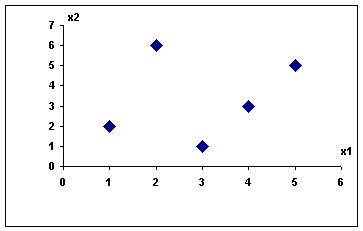
Из рисунка
видно, что наблюдения можно разделить на два множества (наблюдения 1,2 и
наблюдения 3,4,5). Что бы наилучшим образом разделить множества, нужно построить
соответствующую линейную комбинацию переменных
x1 и
x2 - дискриминантную
функцию:
d =
β1*x1 + β2*x2
Обозначим xij среднее значение j-го признака у объектов i-го множества. Тогда для первого множества среднее значение функции будет равно:
d1 = β1*x11 + β2*x12
для второго множества:
d2 = β1*x21 + β2*x22
Коэффициенты дискриминантной функции определяются таким образом, чтобы d1 и d2 как можно больше различались между собой. Требуется максимизировать разность d1 - d2. Вектор коэффициентов B=(β1,β2)T определяется из следующего выражения:
B = C-1(X1 - X2),
где: C - объединенная ковариационная матрица наблюдений;
X1 , X2 - центроиды первого и второго множеств.
Объединенная ковариационная матрица в общем виде определяется из выражения:
C = (X1TX1 + X2TX2)/(n1 + n2 - 2),
где: X1, X2 - матрицы центрированных значений наблюдений двух групп;
n1 , n2 - количество наблюдений в каждой группе.
Для нашего примера матрица C имеет вид:
|
0,83 |
2 |
| 2 | 5,3 |
обратная матрица C-1 имеет вид:
| 13,3 | -5 |
| -5 | 2,1 |
Вектор B имеет вид:
| -3,46 |
| 1,3 |
Таким образом:
d1 = β1*x11 + β2*x12 = -3,46*1,5 + 1,3*4 = 0,01
d2 = β1*x21 + β2*x22 = -3,46*4 + 1,3*3 = -9,94
и разность d1 - d2 составляет:
d1 -d2 = 0,01 + 9,94 = 9,95
Для классификации новых данных нужно определить границу, разделяющую в частном случае две рассматриваемые группы. Такой величиной может быть значение функции, равноудаленное от d1 и d2:
A=(d1 + d2)/2 = (0,01 - 9,94)/2 = -4,965.
Величина A называется константой дискриминации. Объекты расположенные выше прямой:
-3,46*x1 + 1,3*x2 = -4,965
расположены ближе к центру первой группы и могут быть отнесены к этой группе. Представленная функция называется функцией классификации.
