Поисковая система - это программное обеспечение, предоставляющее доступ к коллекции слабоструктурированной информации. Ориентация на слабоструктурированные данные, т.е. данные, которые нельзя представить в виде реляционной таблицы, отличает поисковую систему от СУБД. В данном определении поисковой системы подразумевается информация различного рода, т.е. текст, аудио, видео, изображения и т.п. Однако следует отметить, что именно текстовые данные идеально подходят для описания полной функциональности поисковой системы, т.к. алгоритмы поиска мультимедийной информации, прежде всего, основываются на алгоритмах поиска текста.
Поиск осуществляется тогда, когда в этом возникает потребность. Это информационная потребность часто даже не может быть точно выражена выражена словами, и выражается только в оценке просматриваемых документов - подходит или не подходит. В теории информационного поиска вместо слова "подходит" используют термин "пертинентный документ", а вместо слова "не подходит" - "не пертинентный документ". Субъективно понимаемая цель поиска - найти все пертинентные и только пертинентные документы. Эта цель недостижима.
Мы часто в состоянии оценить пертинентность документа только в сравнении с другими документами. Для этого необходимо некоторое количество непертинентных документов. Эти документы называются - "шум". Слишком большой шум затрудняет выделение пертинентных документов, слишком малый - не дает уверенности в том, что найдено достаточное количество пертинентных документов. Практика показывает, что когда количество непертинентных документов лежит в пределах от 10% до 30%, ищущий чувствует себя комфортно, считая, что количество найденных документов - удовлетворительно. Когда документов много, используется информационно-поисковая система (ИПС). Для общения с ИПС информационная потребность должна быть выражена средствами, которая эта ИПС "понимает" - должен быть сформулирован запрос. Однако, запрос редко может точно выразить информационную потребность. Многие ИПС по разным причинам не могут определить, соответствует ли тот или иной документ запросу. Степень соответствия документа запросу называется релевантностью. Релевантный документ может оказаться непертинентным и наоборот. Например, в случае, когда ищется информация о шлюпочных якорях (кошках), запрос, состоящий из слова "кошка", почти в любой ИПС даст массу релевантных, но непертинентной документов.
Основная задача поисковой системы - минимизировать время, затрачиваемое пользователем на поиск релевантной запросу информации. Традиционно к поисковой системе применяют две основные характеристики: точность и полнота, а точнее, их зависимость. Каждый раз, когда пользователь задает системе запрос, тем самым инициализируя поиск, все документы в коллекции поисковой системы делятся на четыре части, как это показано ниже
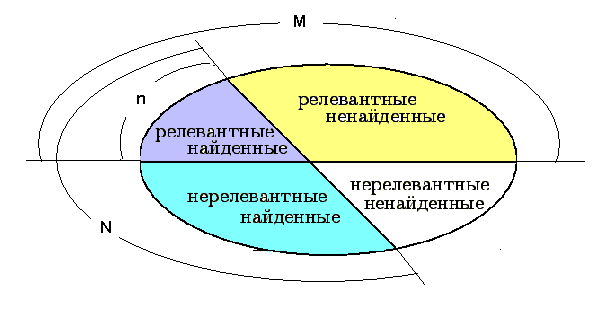
Тогда точность и полнота поиска определяются следующим образом:
Prec=n/N
Rec=n/M ,
где Prec - точность;
n - число найденных релевантных документов;
N - общее число найденных документов;
Rec - полнота;
M - общее число релевантных документов.
Точность определяет один аспект поиска, а именно, насколько хорошо поисковая система способна минимизировать время, затрачиваемое пользователем на поиск релевантной данному запросу информации. Например, если по запросу "Красная площадь" находится 150 документов, в 70 из них содержится словосочетание "Красная площадь", а в остальных просто присутствуют эти слова ("красная баба кричала на всю площадь"), то точность поиска считается равной 70/150 (~0,5). Чем точнее поиск, тем быстрее пользователь находит нужные ему документы, тем меньше "мусора" среди них встречается, тем реже найденные документы не соответствуют запросу.Полнота определяет другой аспект - насколько хорошо система способна найти релевантную данному запросу информацию.